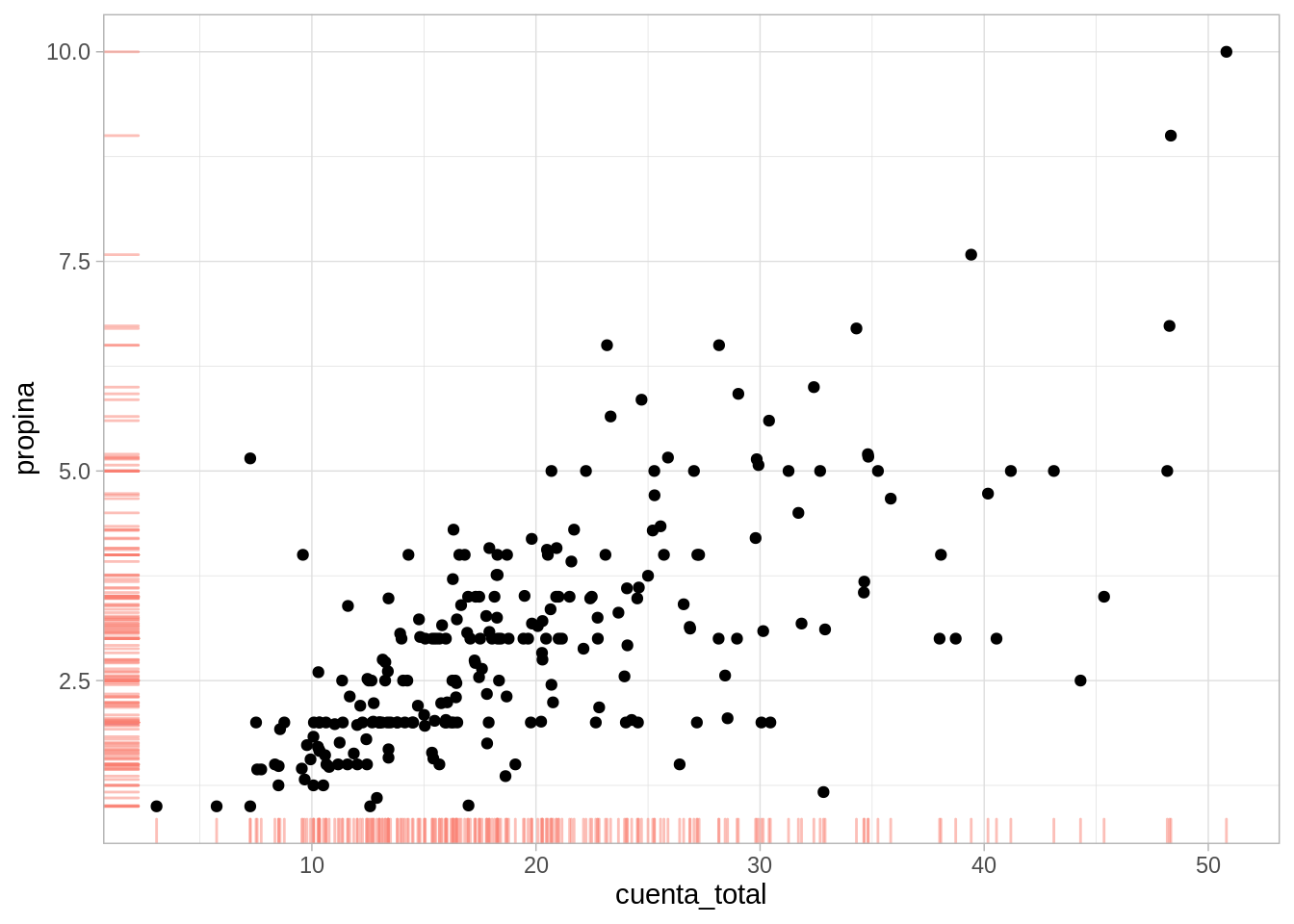
El primer concepto se refiere a entender cómo se distribuyen los datos a los largo de su escala de medición. Comenzamos con un ejemplo: los siguientes datos fueron registrados en un restaurante durante cuatro días consecutivos.
Código
# usamos los datos tips del paquete reshape2propinas <-read_csv("./datos/propinas.csv")slice_sample(propinas, n =10) |>kable() |>kable_paper(full_width =FALSE)
cuenta_total
propina
fumador
dia
momento
num_personas
18.29
3.76
Si
Sab
Cena
4
24.59
3.61
No
Dom
Cena
4
23.68
3.31
No
Dom
Cena
2
30.14
3.09
Si
Sab
Cena
4
14.73
2.20
No
Sab
Cena
2
34.83
5.17
No
Jue
Comida
4
24.71
5.85
No
Jue
Comida
2
30.46
2.00
Si
Dom
Cena
5
15.48
2.02
Si
Jue
Comida
2
12.74
2.01
Si
Jue
Comida
2
Aquí la unidad de observación es una cuenta particular. Tenemos tres mediciones numéricas de cada cuenta: cúanto fue la cuenta total, la propina, y el número de personas asociadas a la cuenta. Los datos están separados según se fumó o no en la mesa, y temporalmente en dos partes: el día (Jueves, Viernes, Sábado o Domingo), cada uno separado por Cena y Comida.
El primer tipo de comparaciones que nos interesa hacer es para una medición numérica es: ¿Varían mucho o poco los datos? ¿Cuáles son valores típicos o centrales? ¿Existen valores muy extremos alejados de valores típicos?
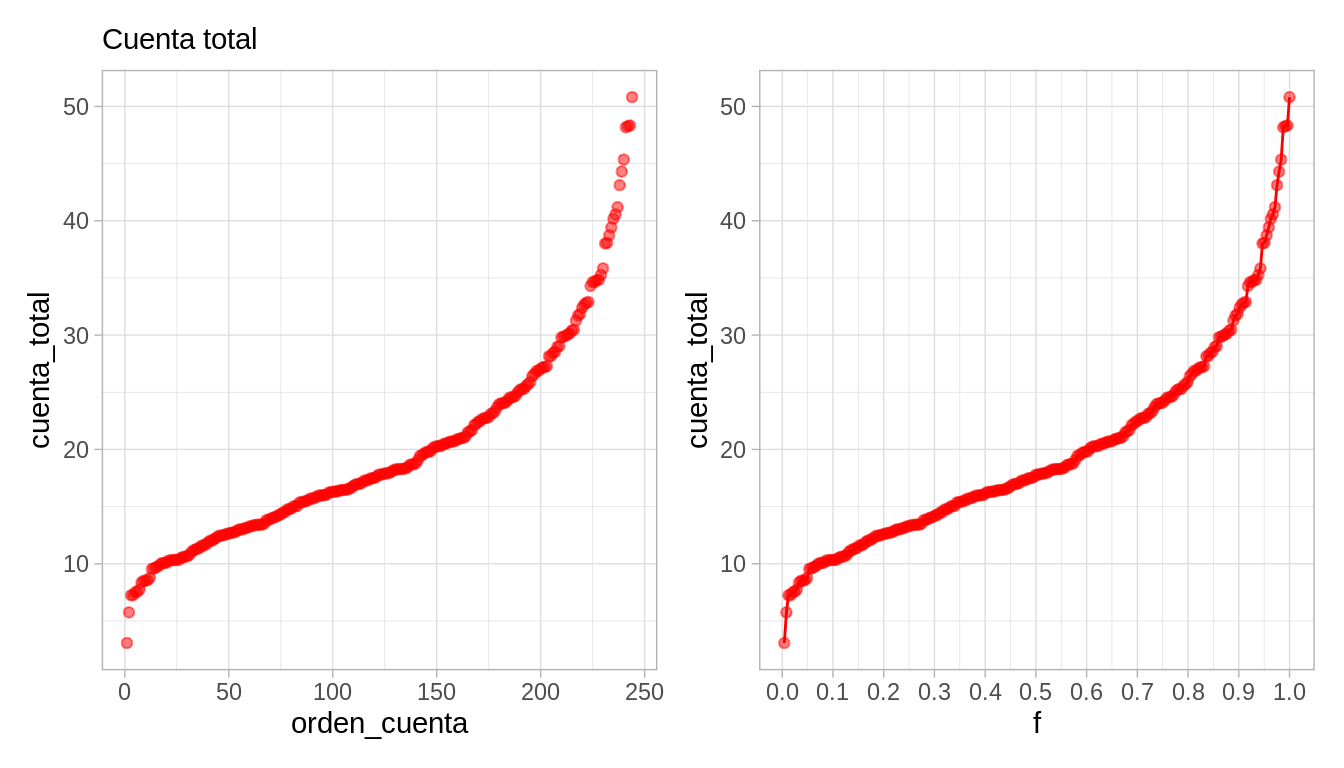
Supongamos entonces que consideramos simplemente la variable de cuenta_total. Podemos comenzar por ordenar los datos, y ver cuáles datos están en los extremos y cuáles están en los lugares centrales:
y graficamos los datos en orden, interpolando valores consecutivos.
A esta función le llamamos la función de cuantiles para la variable cuenta total. Nos sirve para comparar directamente los distintos valores que observamos los datos según el orden que ocupan.
Cuantiles de datos numéricos
El cuantil \(f\) de un bonche de datos numéricos es el valor \(q(f)\), en la escala de medición de nuestros datos, tal que aproximadamente una fracción \(f\) de los datos está por abajo de \(q(f)\).
Al cuantil \(f=0.5\) le llamamos la mediana.
A los cuantiles \(f=0.25\) y \(f=0.75\) les llamamos cuartiles inferior y superior.
Nota: si los datos originales son \(y_1, y_2, \ldots, y_n\), y los mismos datos ordenados son \(y_{(1)}, y_{(2)}, \ldots, y_{(n)}\), entonces si \(f= j/n\), \(q(f) = y_{(j)}\). Si \(f\) toma un valor intermedio entre \((j-1)/n\) y \(j/n\), entonces interpolamos \(y_{(j-1)}\) y \(y_{(j)}\) para encontrar \(q(f)\).
Hay otras maneras de definir los cuantiles que pueden ser más convenientes. Los que estamos usando ahora son los cuantiles tipo 4:
quantile(cuenta$cuenta_total, probs =c(6/244, 239/244), type =4)
2.459016% 97.95082%
7.56 44.30
¿Qué podemos leer en la gráfica de cuantiles?
Dispersión y valores centrales
El rango de datos va de unos 3 dólares hasta 50 dólares
Los valores centrales (del cuantil 0.25 al 0.75, por ejemplo), están entre unos 13 y 25 dólares
Podemos usar el cuantil 0.5 (mediana) para dar un valor central de esta distribución, que está alrededor de 18 dólares.
Y podemos dar resúmenes más refinados si es necesario
El cuantil 0.95 es de unos 35 dólares - sólo 5% de las cuentas son de más de 35 dólares
El cuantil 0.05 es de unos 8 dólares - sólo 5% de las cuentas son de 8 dólares o menos.
Finalmente, la forma de la gráfica se interpreta usando su pendientes, haciendo comparaciones de diferentes partes de la gráfica:
Entre los cuantiles 0.2 y 0.5 es donde existe mayor densidad de datos: la pendiente es baja, lo que significa que al avanzar en los cuantiles, los valores observados no cambian mucho.
Cuando la pendiente es alta, quiere decir que los datos tienen más dispersión local o están más separados.
Y podemos considerar qué sucede en las colas de la distribucion:
La distribución de valores tiene asimetría: el 10% de las cuentas más altas tiene considerablemente más dispersión que el 10% de las cuentas más bajas. A veces decimos que la cola de la derecha es más larga que la cola de la izquierda
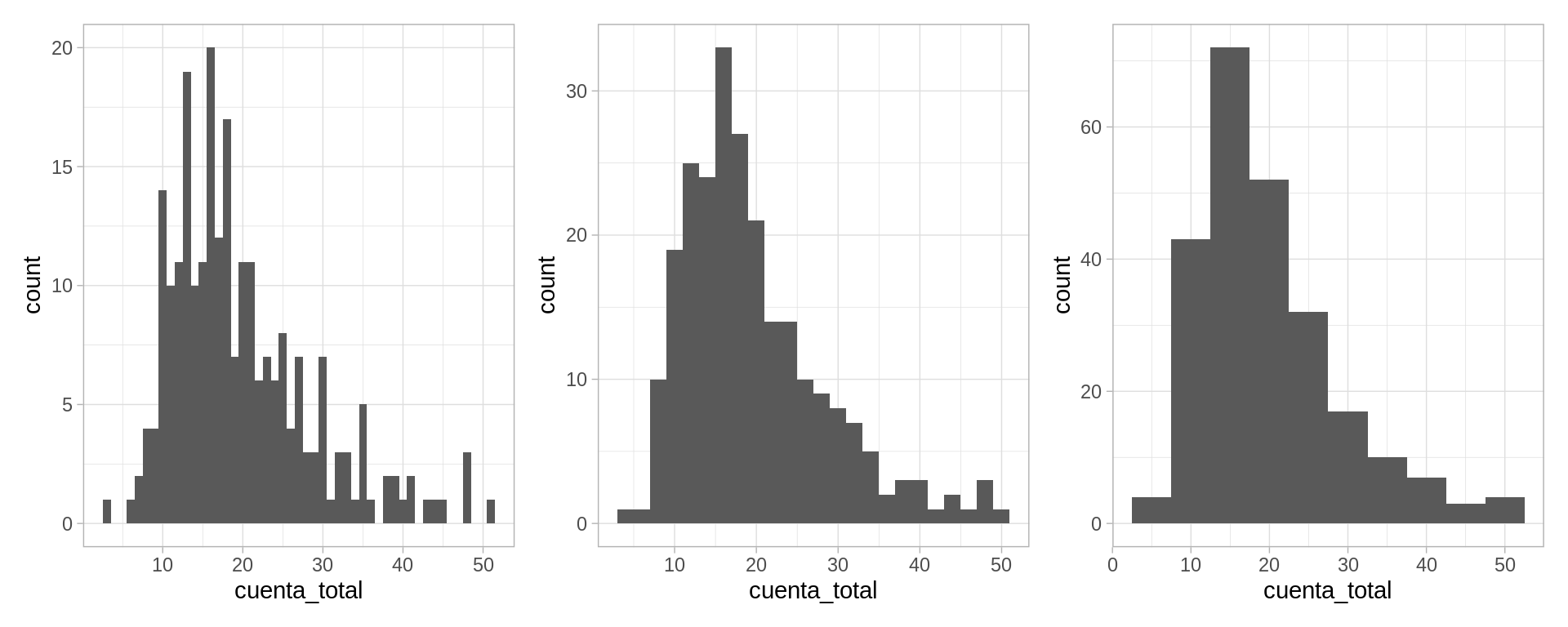
En algunos casos, es más natural hacer un histograma, donde dividimos el rango de la variable en cubetas o intervalos (en este caso de igual longitud), y graficamos cuántos datos caen en cada cubeta. En la siguiente gráfica variamos el ancho de las cubetas:
Es una gráfica más popular, pero perdemos cierto nivel de detalle, y distintas particiones resaltan distintos aspectos de los datos.
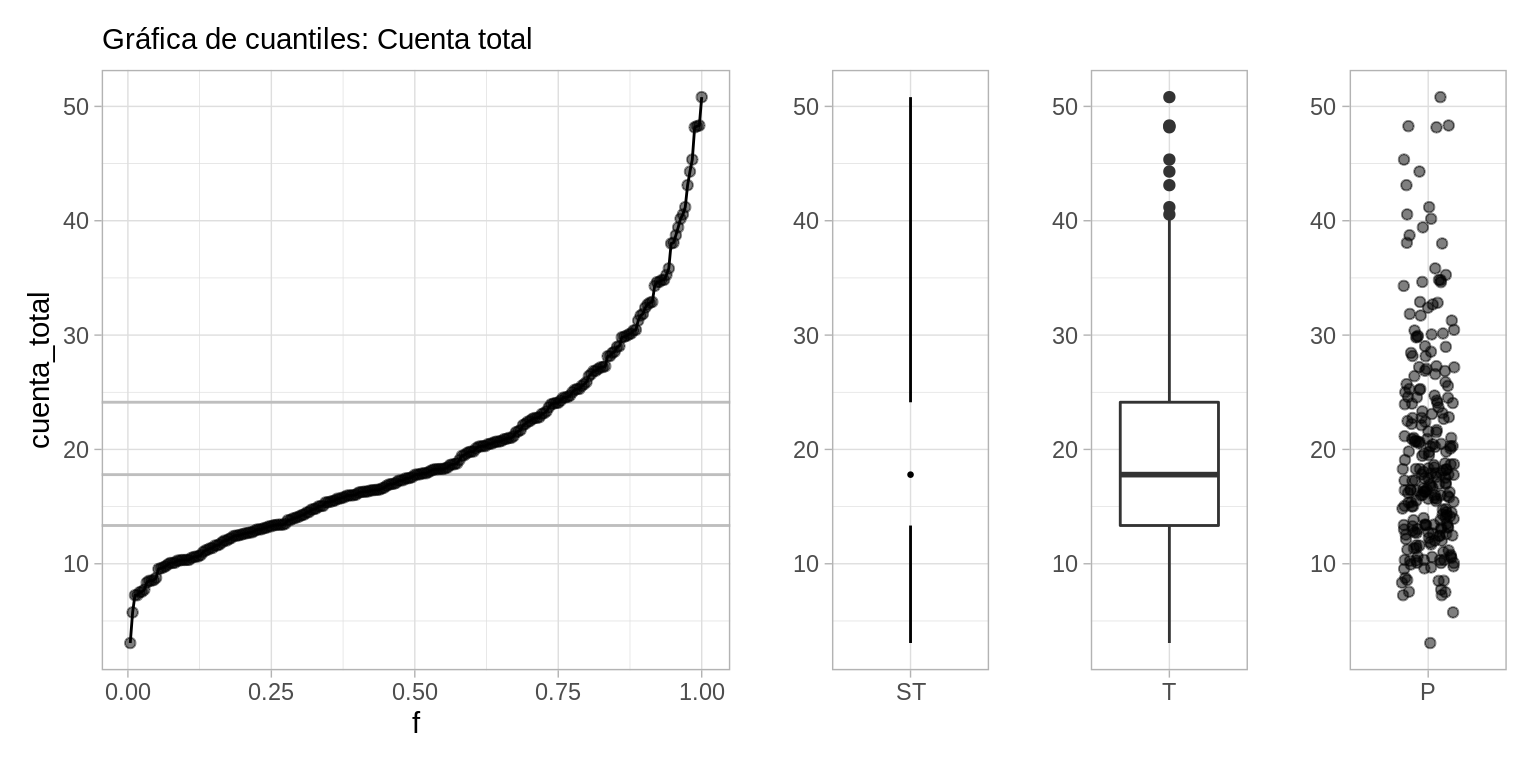
Finalmente, una gráfica más compacta que resume la gráfica de cuantiles o el histograma es el diagrama de caja y brazos. Mostramos dos versiones, la clásica de Tukey (T) y otra versión menos común de Spear/Tufte (ST):
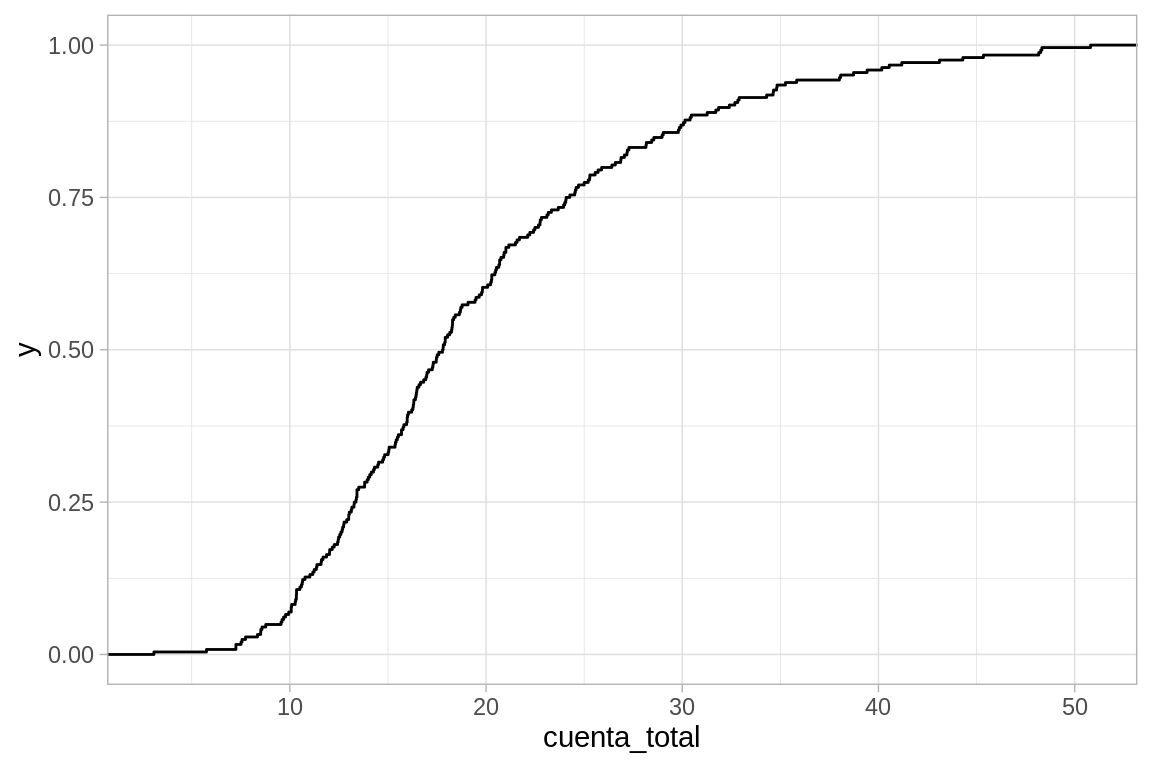
Otra forma de graficar la dispersión de los datos sin perder información es mediante la función de distribución acumulada empírica, o fda empírica. En un sentido, es la inversa de la función de cuantiles:
En esta gráfica, vemos que proporción de los datos que son iguales o están por debajo de cada valor en el eje horizontal.
Nota
En análisis de datos, es más frecuente utilizar la función de cuantiles pues existen versiones más generales que son útiles, por ejemplo, para evaluar ajuste de modelos probabilísticos
En la teoría, generalmente es más común utilizar la fda empírica, que tiene una única definición que veremos coincide con definiciones teóricas.
4.3 Media y desviación estándar
Otras medidas más comunes de localización y dispersión para conjuntos de datos son media y desviación estándar muestral.
La media de un conjunto de datos \(x_1,\ldots, x_n\) es
En general, no son muy apropiadas para iniciar el análisis exploratorio, y se requieren cuidados adicionales al utilizarlas, pues:
Son medidas más difíciles de interpretar y explicar que los cuantiles. En este sentido, son medidas especializadas. Como ejercicio, intenta explicar intuitivamente qué es la media. Después prueba con la desviación estándar. Sin embargo, la mediana o el rango intercuartílico son fáciles de explicar.
No son resistentes a valores atípicos o erróneos. Su falta de resistencia los vuelve poco útiles en las primeras etapas de descripción, y muchas veces requieren transformaciones o cuidados adicionales/supuestos para evitar mal comportamiento por esa falta de resistencia.
Sin embargo,
La media y desviación estándar son computacionalmente convenientes, y para el trabajo de modelado, por ejemplo, tienen ventajas claras (cuando se cumplen supuestos). Por lo tanto regresaremos a estas medidas una vez que estudiemos modelos de probabilidad básicos.
Muchas veces, ya sea por tradición, porque así se ha hecho el análisis antes, conviene usar estas medidas conocidas.
4.4 Distribuciones sesgadas y atípicos
En algunos casos tenemos que trabajar con mediciones que tienen una cola (usualmente la derecha) mucho más larga que la otra. Veamos cuáles son consecuencias típicas.
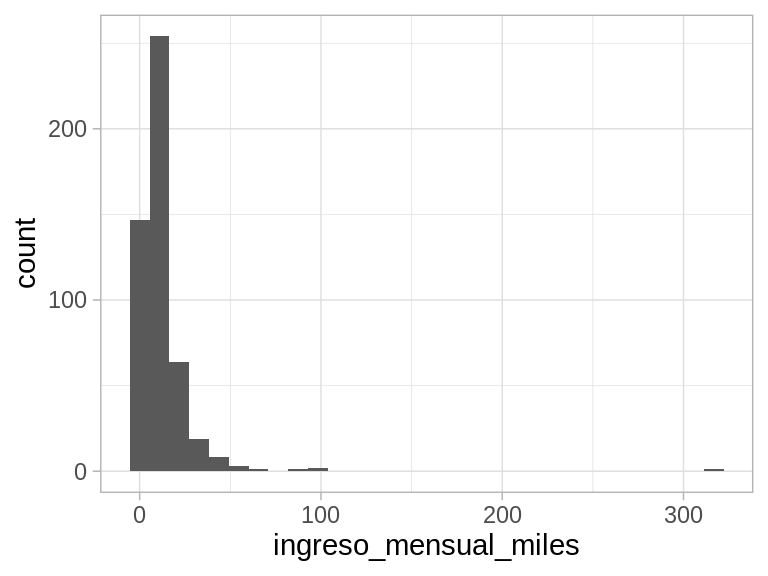
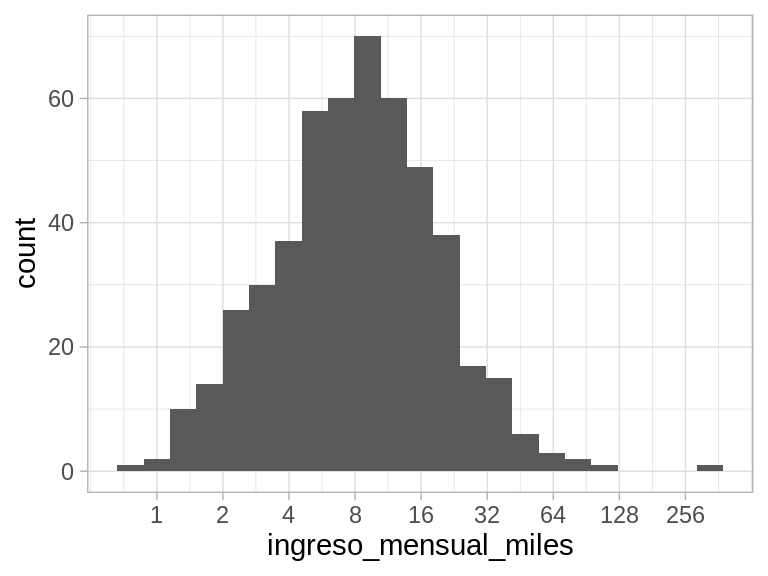
Consideremos por ejemplos una muestra de los datos de ENIGH 2018
donde podemos ver cómo cuando nos movemos a deciles más altos, la dispersión aumenta. Existen algunos valores muy grandes. Un histograma no funciona muy bien con estos datos.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
Nótese que la media de estos datos no es un resúmen muy útil, porque es difícil de interpretar. Por los valores grandes, la media es considerablemente más alta que la mediana:
Por las propiedades de los cuantiles, cualquier cantidad basada en cuantiles que se calcula en escala logarítmica puede pasarase a la escala original transformando
Calculamos primeros unos cuantiles de los precios de las casas:
Código
quantile(casas |>pull(precio_miles))
0% 25% 50% 75% 100%
37.9 132.0 165.0 215.0 755.0
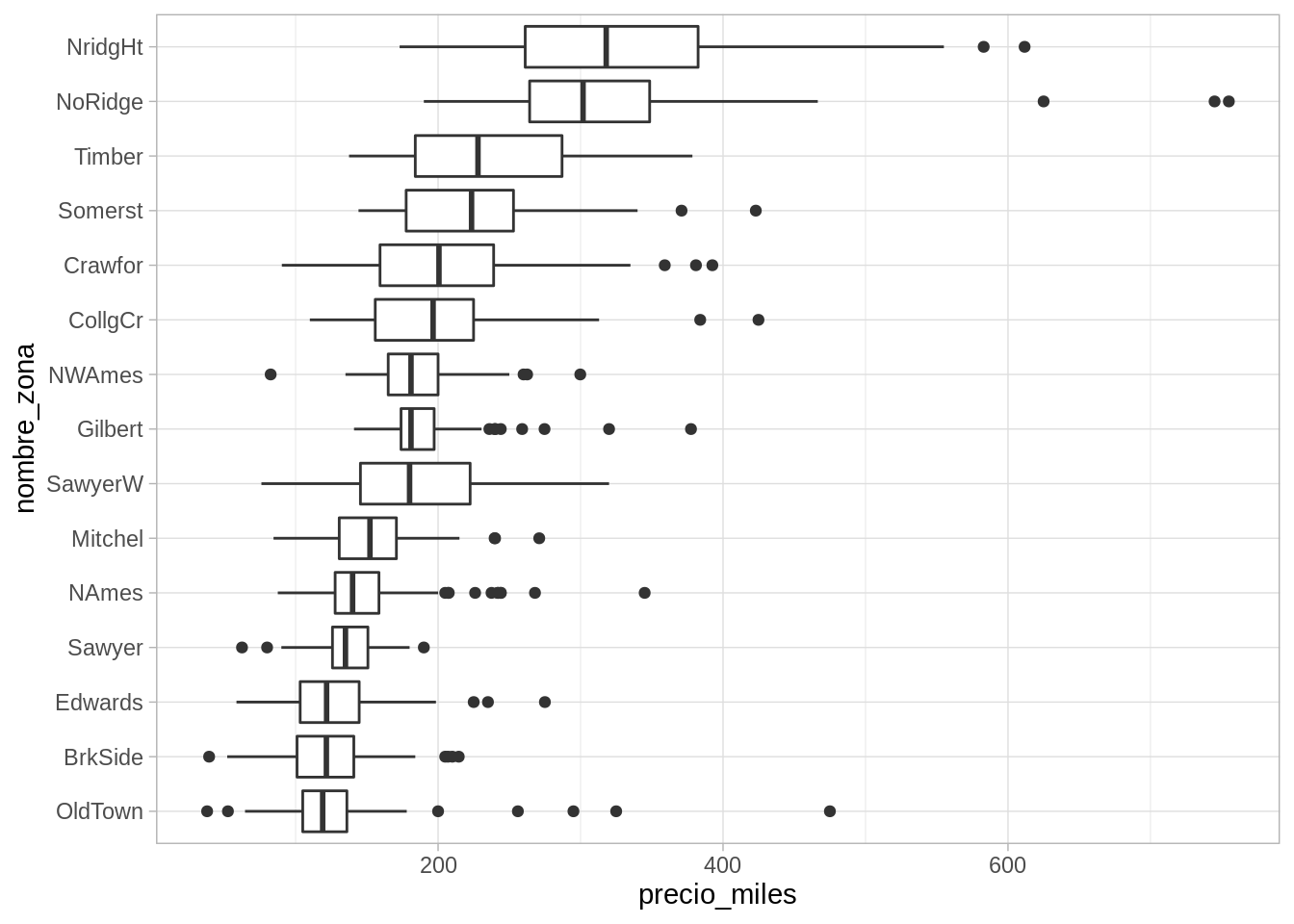
Una primera comparación que podemos hacer es considerar las distintas zonas de la ciudad. Podemos usar diagramas de caja y brazos para comparar precios en distintas zonas de la ciudad:
Código
ggplot(casas, aes(x = nombre_zona, y = precio_miles)) +geom_boxplot() +coord_flip()
Nótese que de cada zona, los datos tienen una cola derecha más larga que la izquierda, e incluso hay valores extremos en la cola derecha que exceden el rango de variación usual. Una razón por la que puede suceder esto es que haya características particulares que agregan valor considerable a una casa, por ejemplo, el tamaño, una alberca, etc.
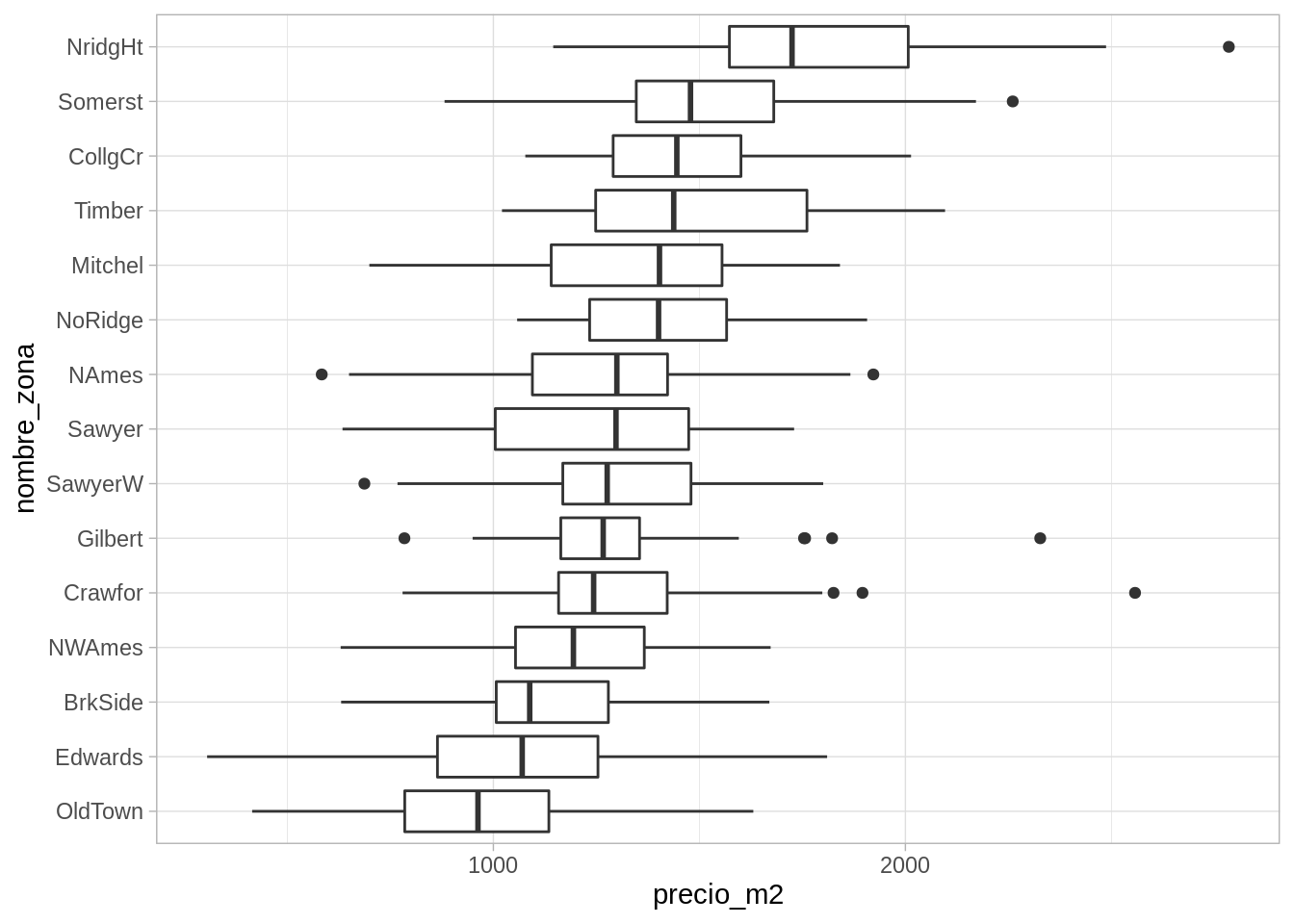
En primer lugar, podemos considerar el área de las casas. En lugar de graficar el precio, graficamos el precio por metro cuadrado, por ejemplo:
Código
ggplot(casas, aes(x = nombre_zona, y = precio_m2)) +geom_boxplot() +coord_flip()
Nótese ahora que la variación alrededor de la media es mucho más simétrica, y ya no vemos tantos datos extremos. Aún más, la variación dentro de cada zona parece ser similar, y podríamos describir restos datos de la siguiente forma:
Cuantificamos la variación que observamos de zona a zona y la variación que hay dentro de zonas. La variación que vemos entre las medianas de la zona es:
Nótese que este último paso tiene sentido pues la variación dentro de las zonas, en términos de precio por metro cuadrado, es similar. Esto no lo podríamos hacer de manera efectiva si hubiéramos usado el precio de las casas sin ajustar por su tamaño.
Y vemos que la mayor parte de la variación del precio por metro cuadrado ocurre dentro de cada zona, una vez que controlamos por el tamaño de las casas. La variación dentro de cada zona es aproximadamente simétrica, aunque la cola derecha es ligeramente más larga con algunos valores extremos.
4.6 Factor y respuesta numéricos (opcional)
En las secciones anteriores vimos cómo describir “bonches” de datos numéricos y categóricos. Adicionalmente, vimos cómo usar esas técnicas para comparar las descripciones a lo largo de varios subconjuntos de los datos.
En estos casos, muchas veces llamamos factor a la variables que forma los grupos, y respuesta a la variable que estamos comparando. Por ejemplo, en el caso de los precios de las casas comparamos el precio de las casas (respuesta) dependiendo del vecindario (factor) dónde se encuentran.
Cuando tenemos una factor numérico y una respuesta numérica podemos comenzar haciendo diagramas de dispersión. Por ejemplo,
Ejemplo: cuenta total y propina
Código
library(tidyverse)library(patchwork)library(kableExtra)# usamos los datos tips del paquete reshape2propinas <-read_csv("./datos/propinas.csv")
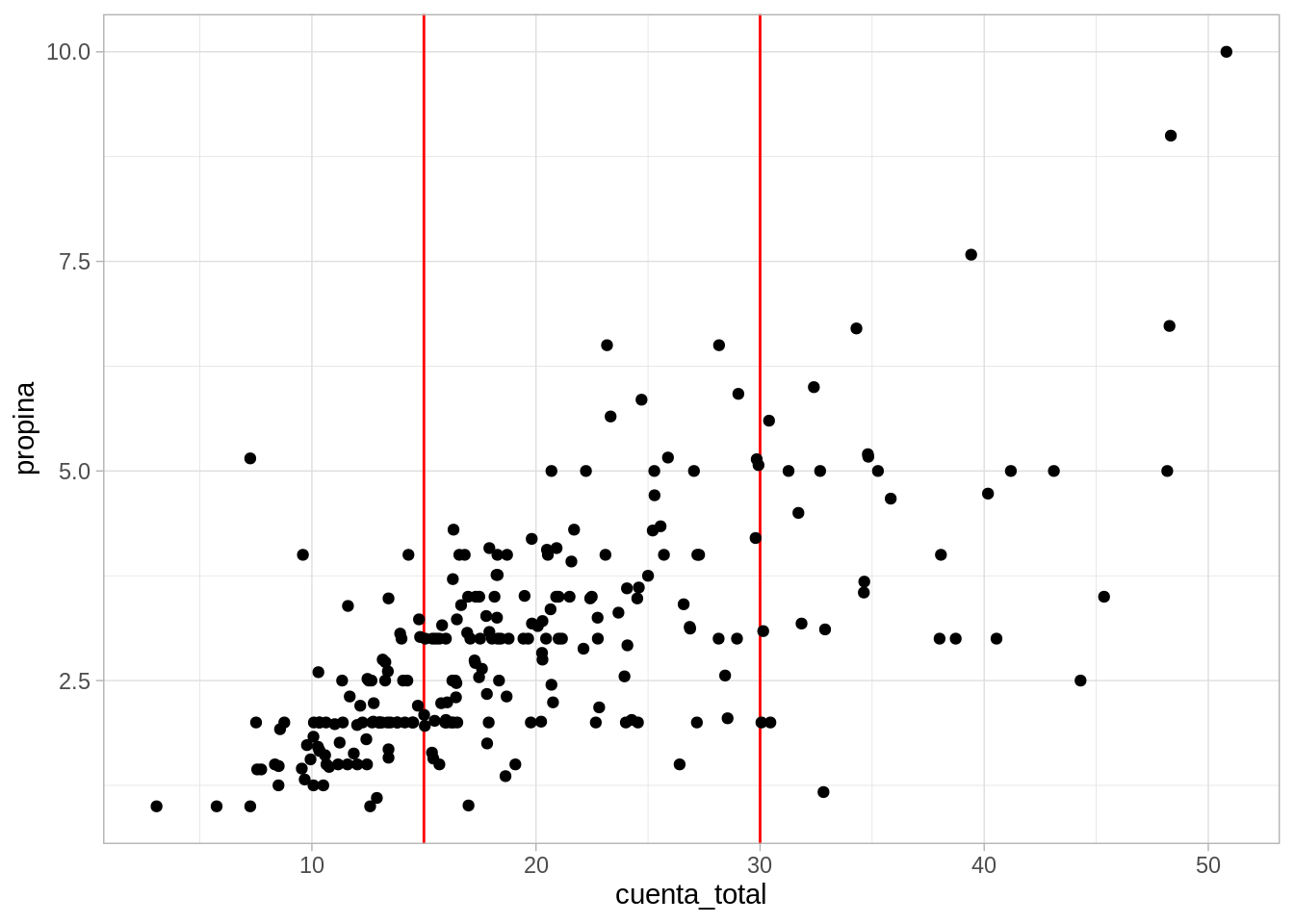
Ahora queremos comparar la distribución de propina (respuesta) para distintos niveles del factor (cuenta_total). Por ejemplo, ¿cómo se compara propina cuando la cuenta es de 15 dólares vs 30 dólares?
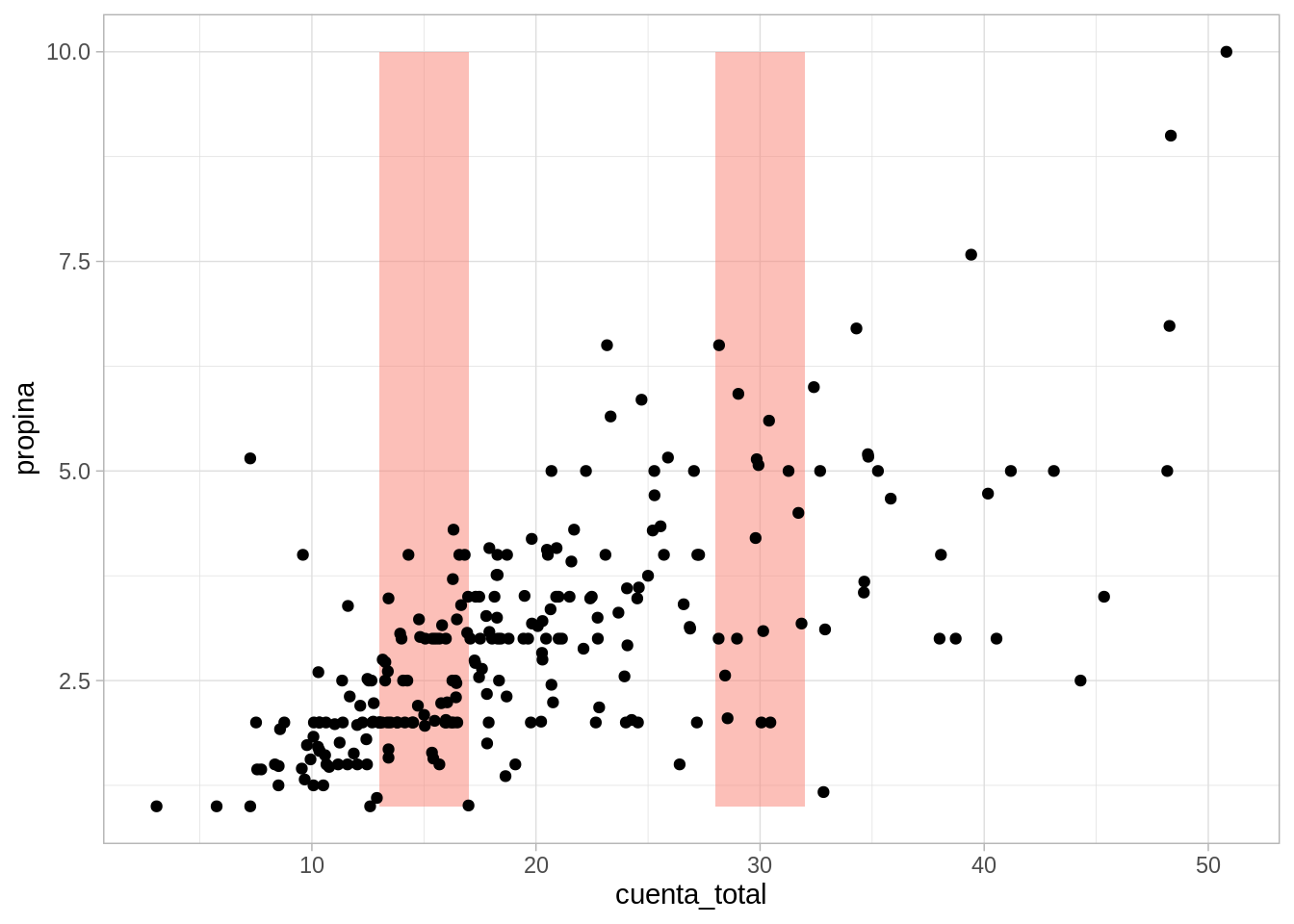
Vemos que los datos de propinas alrededor de 30 dólares están centrados en valores más grandes que en el nivel de 15 dólares, y también que hay más dispersión en el nivel de 30 dólares. Sin embargo, vemos que tenemos un problema: existen realmente muy pocos datos que tengan exactamente 15 o 30 dólares de cuenta. La estrategia es entonces considerar qué sucede cuando la cuenta está alrededor de 15 o alrededor de 30 dólares, donde alrededor depende del problema particular y de cuántos datos tenemos:
Código
ggplot(propinas, aes(x = cuenta_total, y = propina)) +geom_ribbon(aes(xmin =13, xmax =17), fill ="salmon", alpha =0.5) +geom_ribbon(aes(xmin =28, xmax =32), fill ="salmon", alpha =0.5) +geom_point()
Considerando estos grupos de datos, podemos describir de las siguiente forma, por ejemplo:
Donde confirmamos que el nivel general de propinas es más alto alrededor de cuentas de total 30 que de total 15, y la dispersión también es mayor. Podríamos hacer un diagrama de caja y brazos también.
4.7 Suavizadores locales
El enfoque del ejemplo anterior puede ayudar en algunos casos nuestra tarea descriptiva, pero quisiéramos tener un método más general y completo para entender cómo es una respuesta numérica cuando el factor es también numérico.
En este caso, podemos hacer por ejemplo medias o medianas locales. La idea general es, en términos de nuestro ejemplo de propinas:
Queremos producir un resumen en un valor de cuenta total \(x\).
Consideramos valores de propina asociados a cuentas totales en un intervalo \([x-e, x+e]\).
Calculamos estadísticas resumen en este rango para la respuesta
Usualmente también ponderamos más alto valores que están cerca de \(x\) y ponderamos menos valores más lejanos a \(x\)
Este tipo de suavizadores se llaman a veces suavizadores loess (ver (Cleveland 1993)).
Por ejemplo,
Código
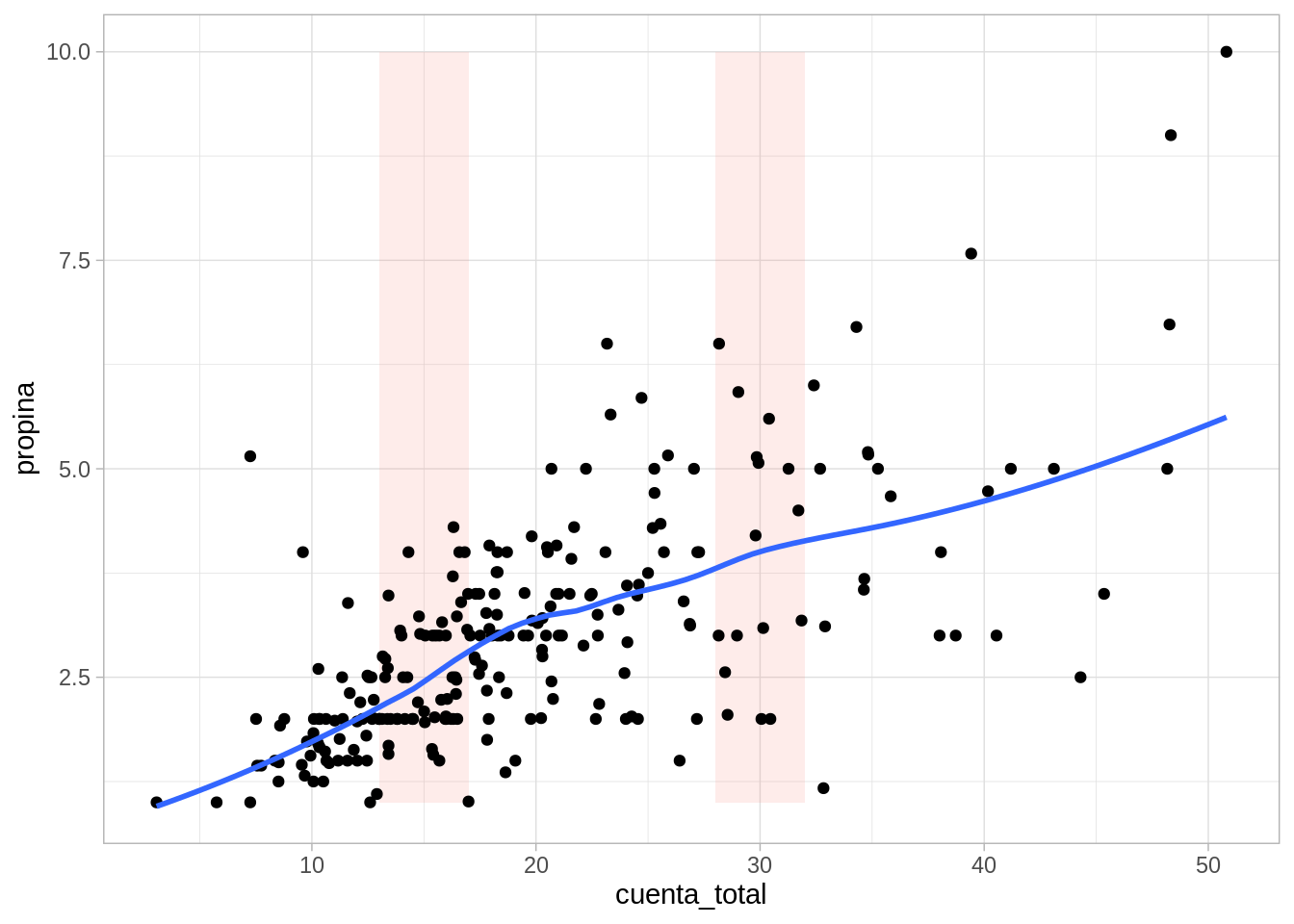
ggplot(propinas, aes(x = cuenta_total, y = propina)) +geom_ribbon(aes(xmin =13, xmax =17), fill ="salmon", alpha =0.15) +geom_ribbon(aes(xmin =28, xmax =32), fill ="salmon", alpha =0.15) +geom_point() +geom_smooth(method ="loess", span =0.5, degree=0, method.args =list(family ="symmetric"), se =FALSE)
Código
# symmetric es un método robusto iterativo, que reduce el peso de atípicos
El parametro span controla el tamaño de la ventana de datos que se toma en cada punto. Nótese como alrededor de 15 y 30 los valores por donde pasa el suavizador son similares a las medianas que escribimos arriba.
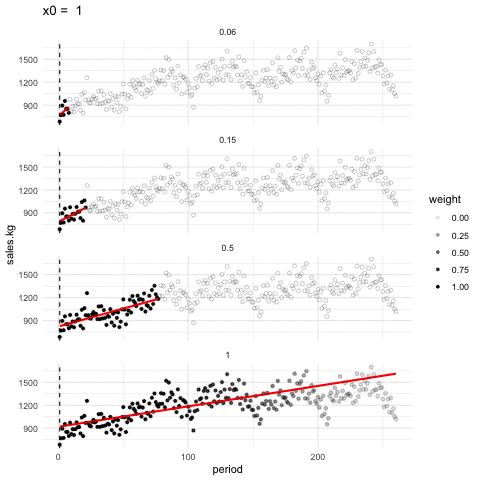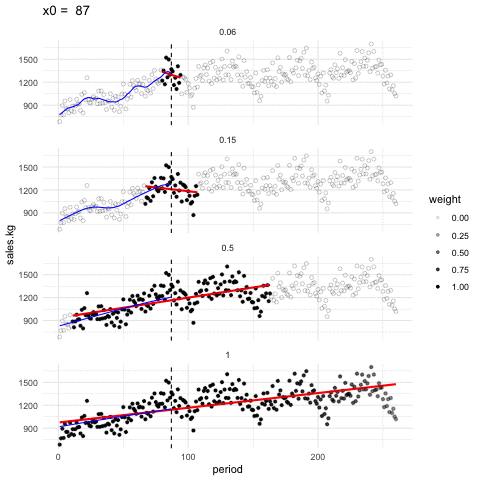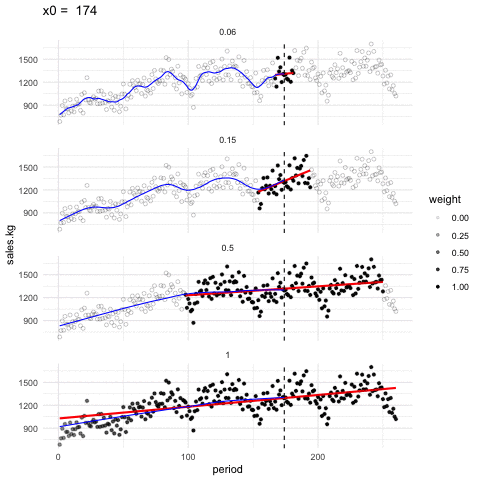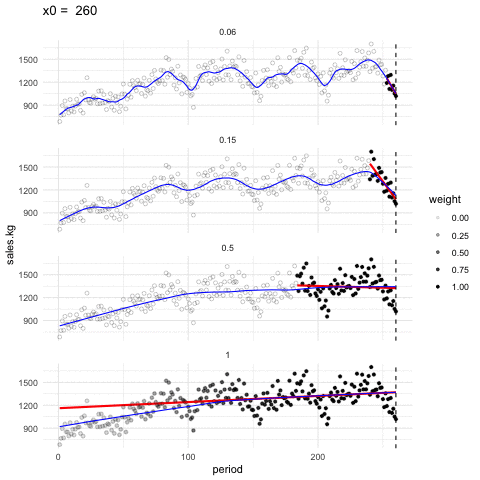
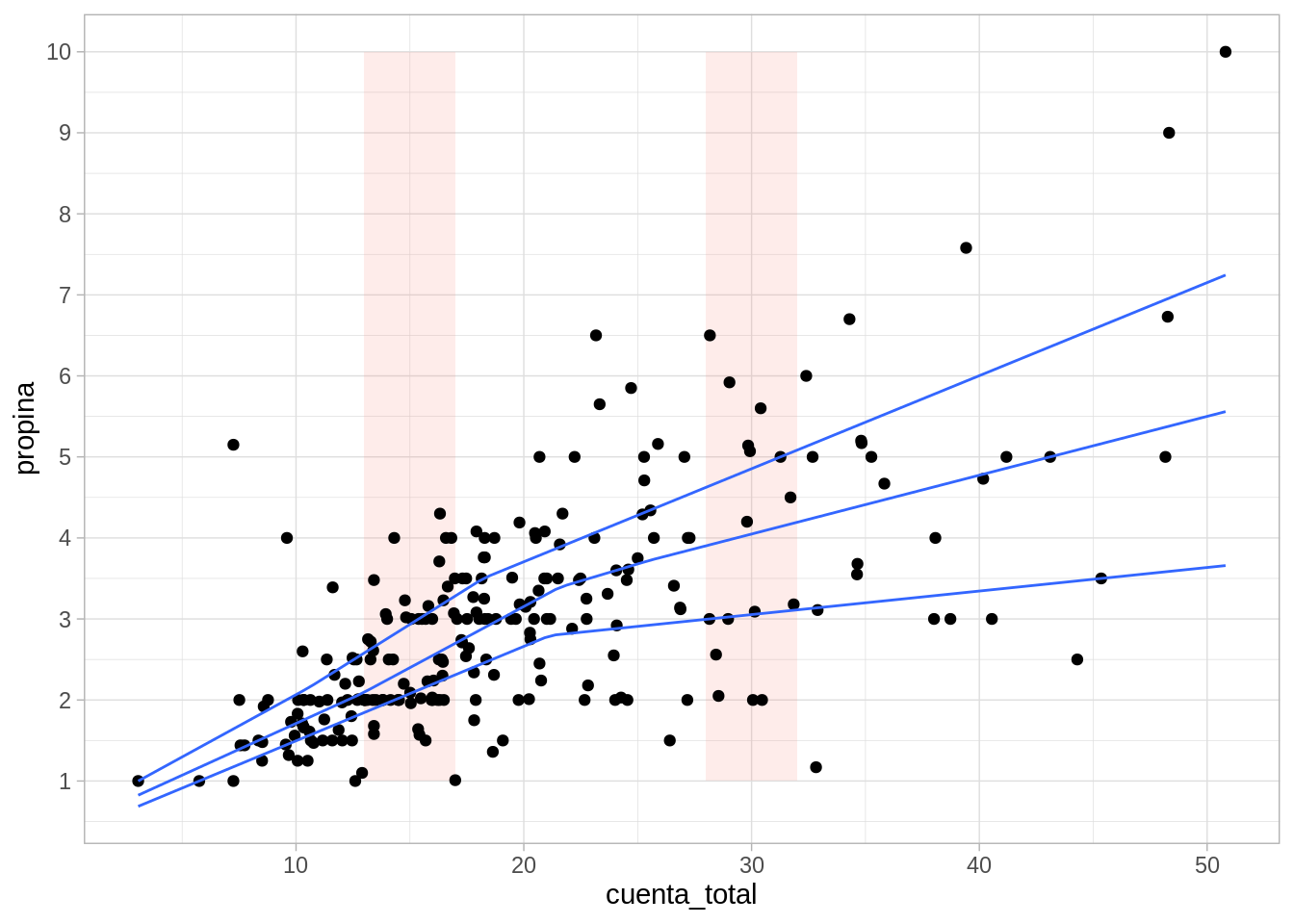
Podemos ajustar en cada ventana tambien rectas de minimos cuadrados, y obtener un suavizador de tipo lineal. En la siguiente gráfica mostramos cómo funciona este suavizador para distintos tamaños de ventanas (span)
Suavizador loess
Los suavizadores loess tienen como fin mostrar alrededor de qué valor se distribuye la respuesta (eje vertical) para distintos valores del factor (eje horizontal). Se escoge span suficientemente baja de forma que mostremos patrones claros en los datos y casi no capturemos variación debida a los tamaños de muestra chicos.
En la animación anterior, un valor de span de 0.15 funciona apropiadamente, uno de 0.05 es demasiado bajo y uno de 1.0 es demasiado alto. Es importante explorar con el valor de span pues depende de cuántos datos tenemos y cómo es su dispersión.
Podemos también mostrar estimaciones de medianas y cuantiles de la siguiente forma (nota: es necesario escoger lambda con cuidado, cuanto más alto sea lambda más suave es la curva obtenida):
Finalmente, el entendimiento de los datos nos permite también hacer gráficas más útiles. En este caso particular podría, por ejemplo, calcular el porcentaje de la propina sobre la cuenta total:
Para cuentas relativamente chicas (10 dólares, el porcentaje de propina está por encima de 15%). Este porcentaje tiende a reducirse a valores 10% y 15% para cuentas más grandes
Existe variación considerable alrededor de estos valores centrales. El rango intercuartiles es aproximadamente de 5 puntos porcentuales.
O de manera más resumida:
La mediana de propinas está ligeramente por arriba de 15% para cuantas relativamente chicas. Esta mediana baja hasta alrededor de 10%-15% para cuentas más grandes (más de 40 dólares)
La mitad de las propinas no varía más de unos 3 puntos porcentuales alrededor de estas medianas.
Existen propinas atípicas: algunas muy bajas de 1 dólar, muy por debajo del 15%, y ocasionalmente algunas muy altas en porcentaje. Estas últimas ocurren ocasinalmente especialmente en cuentas chicas (por ejemplo, una propina de 1 dólar en una cuenta de 3 dólares).
Cleveland, William S. 1993. Visualizing Data. Hobart Press.