En esta parte consideramos hacer inferencia a una población. Quiséramos decir algo acerca de la mediana de una población cuando solo tenemos información parcial.
En este ejemplo, queremos aprender acerca de los precios de casas en una región determinada (los precios están en miles de dólares).
Supongamos que tenemos la siguiente datos, que sólo son parte de la población:
Supongamos que queremos estimar el valor \(m\) que es la mediana poblacional. Este valor tiene la propiedad de que separa a los datos en dos grupos de tamaño igual.
Tip
Estimar en este caso significa dar un rango donde es creíble que está el valor poblacional. No tiene sentido dar un sólo valor pues no conocemos la población total, así que tendremos incertidumbre de dónde está la mediana verdadera
Para construir estos rangos haremos algunos cálculos básicos.
En primer lugar, si observáramos un valor \(y\) en la muestra, ¿cuál es la probabilidad de que caiga por arriba de la mediana? Si no sabemos cómo se extrajo la muestra, o se extrajo bajo un mecanismo complicado, esta pregunta es difícil de contestar.
Sin embargo, si este valor se extrajo tomando un valor al azar entre todos los de la población, entonces sabemos que la probabilidad es
\[P(y <= m) = 0.5\]
Aleatorización al rescate
Supondremos que cada elemento de la muestra se extrajo de la población total al azar, cada uno de manera independiente de los otros.
Para poblaciones finitas, esto equivale a:
Seleccionamos un elemento al azar de la población, donde todos tienen la misma probabildad de ser seleccionado, por ejemplo seleccionando un número de una bolsa que corresponde a cada elemento de la población
Repetimos 1, considerando que es posible sacar al mismo elemento más de una vez.
A este proceso le llamamos muestreo aleatorio simple con reemplazo, que cuando la población es grande y la muestra relativamente chica, prácticamente es igual que hacer el muestreo sin reemplazo. Más adelante discutiremos cómo generalizar a procesos aleatorios diferentes.
Con esta idea básica, podríamos por ejemplo calcular: ¿cuál es la probabilidad de que la mediana esté entre el mínimo y el máximo de la muestra?
Denotemos por \(y_1,y_2,\ldots, y_n\) la muestra observada. Denotaremos a la muestra ordenada del valor más chico al valor más grande como
\[y_{(1)}, y_{(2)}, \ldots, y_{(n)}\]
Nuestra primera pregunta entonces es:
¿Cuál es la probabilidad de el valor de la mediana verdadera esté en el intervalo \([y_{(1)}, y_{(20)}]\)?
Respuesta: La probabilidad de que la mediana esté por debajo del mínimo \(y_{(1)}\) de la muestra es \((1/2)^n\), pues todos los valores de la muestra tienen que caer por arriba de la mediana. La probabilidad de que la mediana esté por arriba del máximo \(y_{(1)}\) es también \((1/2)^n\). Así que la probabilidad de el verdadero valor de la mediana esté en este intervalo es de \(2(1/2)^n\).
Esta es la probabilidad de tirar solamente soles o solamente águilas en \(n\) tiradas de una moneda, Si \(X\) denota el número de soles obtenidos en \(n\) tiradas de moneda, buscamos calcular la probabilidad de que la mediana esté en intervalo como
\[1 - P(X > n - 1) - P(X \leq 0) = 1 - 2(1/2)^n\]
Código
#! code-fold: falsen <-20bajo <-1alto <- n - bajo +11-pbinom(alto -1, 20, 0.5, lower.tail =FALSE) -pbinom(bajo -1, 20, 0.5)
[1] 0.9999981
Código
1-2*(1/2)^20
[1] 0.9999981
Prácticamente es seguro que este intervalo contenga a la media verdadero. Esto no es muy informativo. Probemos ahora con \([y_{(2)}, y_{(n-1)}]\). Por un argumento similar, la probabilidad de la mediana verdadera esté en este intervalo es:
Código
#! code-fold: falsen <-20bajo <-2alto <- n - bajo +11-pbinom(alto -1, 20, 0.5, lower.tail =FALSE) -pbinom(bajo -1, 20, 0.5)
[1] 0.9999599
Esto también es altamente probable. Sin embargo, la probabilidad de la mediana poblacional esté entre \([y_{(7)}, y_{(14)}]\) es al menos
Código
#! code-fold: falsen <-20bajo <-7alto <- n - bajo +11-pbinom(alto -1, 20, 0.5, lower.tail =FALSE) -pbinom(bajo -1, 20, 0.5)
[1] 0.8846817
Así, este intervalo tiene probabilidad de casi 90% de probabilidad de contener al verdadero valor:
Esta es una probabilidad que se refiere al conjunto de muestras posibles de los datos. Es altamente probable que este intervalo cubra al verdadero valor.
Y este es un intervalo de confianza de cerca de 90% para la mediana de la población. Cuando tomamos muestras más grandes, podemos obtener mejores precisiones. Por ejemplo, para una muestra de 151 casas, usaríamos
Código
n <-151bajo <-65alto <- n - bajo -1cobertura <-1-pbinom(alto -1, n, 0.5, lower.tail =FALSE) -pbinom(bajo -1, n, 0.5)cobertura
Esto intervalos tienen la garantía inferencial, y no es necesario hacer ningún supuesto, excepto en que la muestra se escoge al azar.
10.1 Motivación de remuestreo
Podemos pensar en este procedimiento de una manera diferente, sin tener que hacer los cálculos de probabilidades para las estadísticas de orden.
Supongamos que escogemos la muestra de casas al azar de manera independiente. Nuestra pregunta es:
Dada la información de la muestra, qué podemos decir de los valores que no observamos?, y finalmente, ¿qué información nos da sobre la mediana poblacional?
Nótese en primer lugar, igual que antes, que no podemos decir algo definitivo acerca de la muestra particular que obtuvimos. Sin embargo, podemos decir qué puede pasar con alta probabilidad, quitando casos excepcionalmente raros, y basar nuestra inferencia en los casos con la mayor parte de la probabilidad.
Nuestra muestro ordenada la escribimos como \(y_{(1)}\leq y_{(2)}\leq \cdots \leq y_{(n)}\). Podemos considerar los intervalos aleatorios:
que cubren todos los valores posibles que puede haber en la población.
Ahora consideramos un dato \(y\) extraído también al azar de la población. Es igualmente probable que \(y\) caiga en cualquiera de los intervalos \(I\). Para demostrar esto, considera que pasaría si tomaras una muestra de tamaño \(n+1\). Todos los ordenamientos de \(y_1, y_2, \ldots, y_n, y_{n+1}\) son igualmente probables: esto implica que es igualmente probable que \(y_{n+1}\) caiga en cualquiera de estos intervalos (probabilidad \(1/{(n+1)}\)).
Podemos imputar nuestra población entera tomando escogiendo para cada valor no observado un intervalo al azar de manera equiprobable.
Calculamos dónde puede estar la mediana para esta población.
Repetimos los dos anteriores una gran cantidad de veces para ver todos los posibles valores que podría tomar la mediana dada la información que tenemos de la muestra.
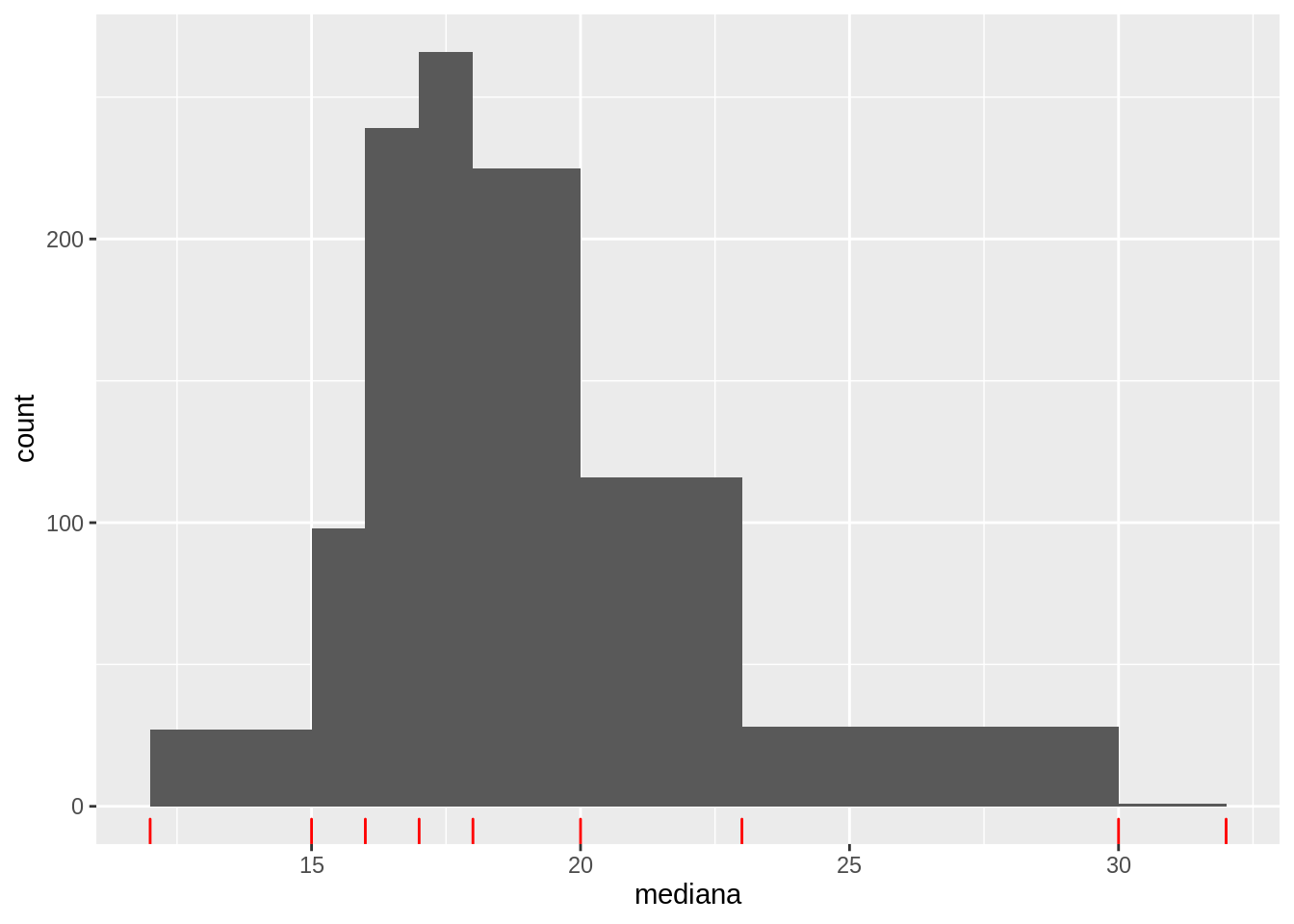
Veamos un ejemplo chico ilustrado para entender la idea. Supongamos que tenemos una población de tamaño 25, y que tomamos una muestra de 8 elementos al azar. Los valores obtenidos, ordenados, son 12, 15, 16, 17, 18, 20, 23, 30, 32. Tenemos entonces 9 intervalos que considerar.
Hacemos ahora el paso el paso 1, y la población imputada ordenada de chica a grande es:
Nótese que como al final vamos a dar un intervalo con extremos en los datos, en realidad no importa mucho qué valor esté representado por las estrellas (excluyendo el caso extremo de que la todos más de la mitad de las estrellas estén por abajo/arriba de todos los datos, lo cual es poco probable). Podemos contar las estrellas en cada posición como un valor en los datos, y ver entre qué valores cae la mediana. De esta forma podríamos encontrar un intervalo que contenga con probabilidad alta a la mediana poblacional.
Aunque arriba imputamos la población completa, una manera más simple de hacer esto es la siguiente, de forma aproximada:
Tomamos una muestra con reemplazo de tamaño 8 de la muestra \(12,15,16,17,20,23,30,32\).
Calculamos la mediana de esta nueva remuestra.
Repetimos los dos anteriores una gran cantidad de veces para ver todos los posibles valores que podría tomar la mediana dada la información que tenemos de la muestra.
Y podemos calcular por ejemplo intervalo de 80% tomando cuantiles de las medias remuestreadas:
Código
quantile(remuestreo_med$mediana, c(0.1, 0.9))
10% 90%
16 23
10.2 Ejemplo: precios de casas
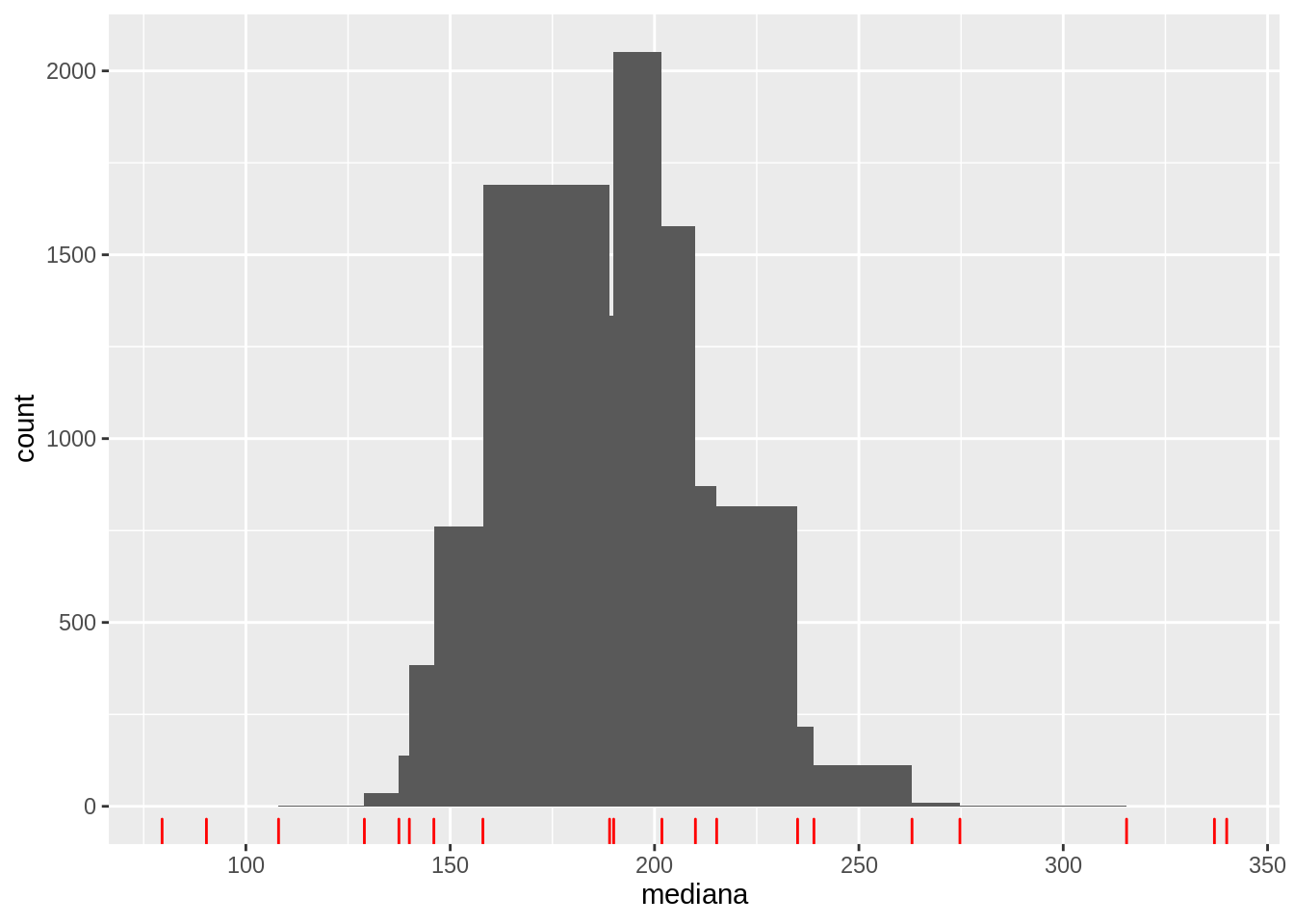
Este proceso se llama remuestreo, y consiste en que una vez que tenemos un estimador para una cantidad poblacional, podemos remuestrar la muestra original, calcular nuestro estimador en cada caso, y así obtener una distribución de posibles valores que puede tener la mediana poblacional. Lo hacemos a continuación para nuestro ejemplo de la mediana de los precios de casas:
quantile(remuestras$mediana, c(0.051, 0.948), type =8)
5.1% 94.8%
146 235
y obtenemos un resultado idéntico al primer argumento de arriba. La cobertura es cercana ser exacta, y no afecta al resultado lo que sucede en las colas de la distribución, gracias a que estamos usando la mediana.
10.3 Remuestreo para otras estadísticas
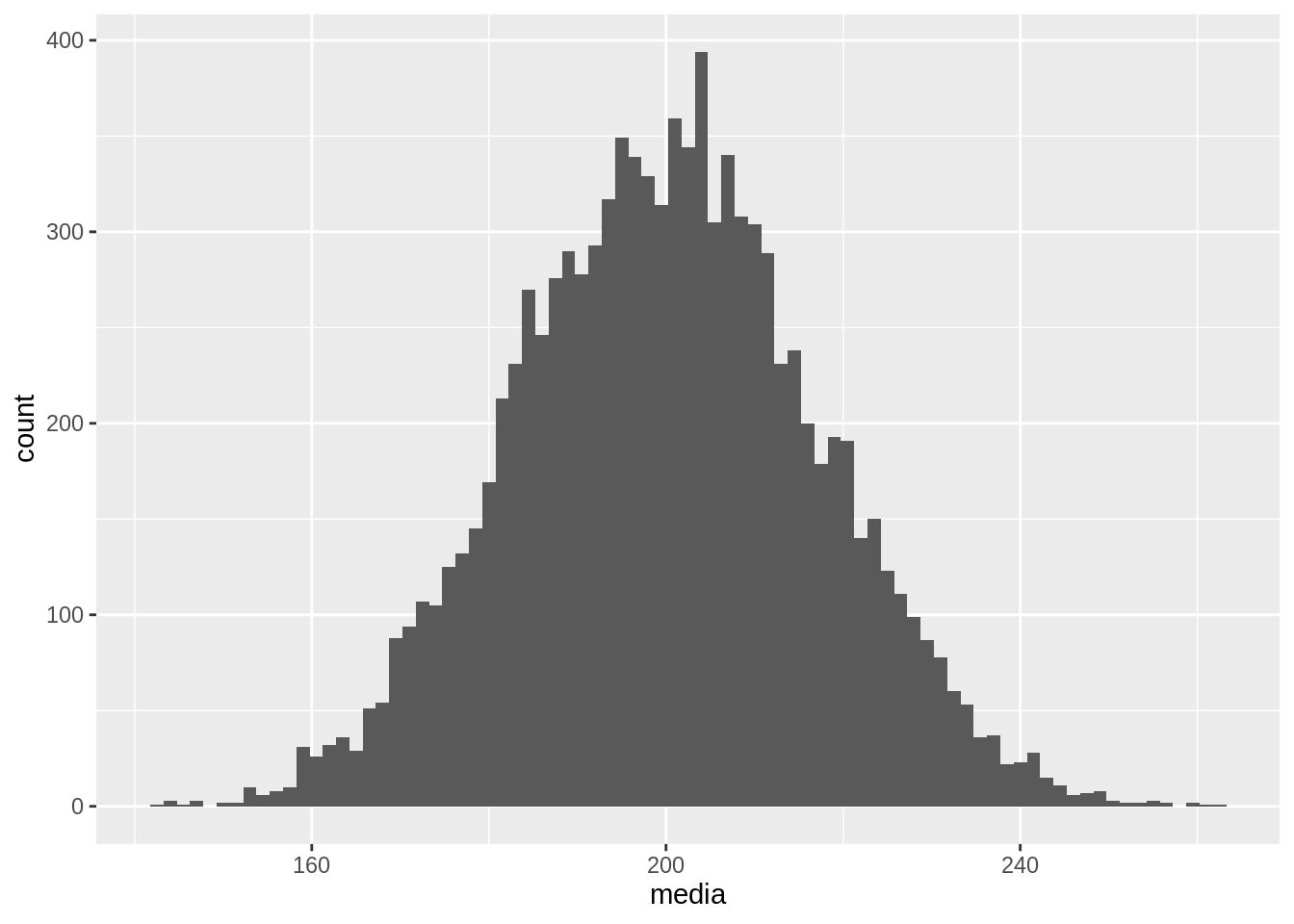
Podemos repetir este método para otras estadísticas como la media. Para el ejemplo de casas:
Motivamos el remuestreo (bootstrap) usando el ejemplo de estimación de la mediana población, donde es posible encontrar un intervalo exacto. El remuestreo se puede usar para muchas otras estadísticas difíciles de tratar teóricamente, y en general su comportamiento es bueno en relación a la cobertura.
Sin embargo, para estadísticas arbitrarias es difícil cumplir de manera exacta las garantías inferenciales (por ejemplo, cuando la distribución tiene una cola muy larga). Veremos como tratar este problema más adelante.